From my learnings across the years, I noticed a pattern within organisations. There is a clash between the parts of the organisation that manages capital expenditure (CAPEX) and the others that manage operating expenditure (OPEX). Let’s use the Wikipedia definitions to expand on those two concepts:
Capital expenditure from Wikipedia:
Capital expenditure or capital expense (capex or CAPEX) is the money an organisation or corporate entity spends to buy, maintain, or improve its fixed assets, such as buildings, vehicles, equipment, or land. It is considered a capital expenditure when the asset is newly purchased or when money is used towards extending the useful life of an existing asset, such as repairing the roof.
Operating expenditure from Wikipedia:
An operating expense, operating expenditure, operational expense, operational expenditure or opex is an ongoing cost for running a product, business, or system. Its counterpart, a capital expenditure (capex), is the cost of developing or providing non-consumable parts for the product or system. For example, the purchase of a photocopier involves capex, and the annual paper, toner, power and maintenance costs represent opex. For larger systems like businesses, opex may also include the cost of workers and facility expenses such as rent and utilities.
I added the definitions of CAPEX and OPEX to the article since, typically, they are not in the IT lexicon. But they are crucial for the observed behaviour.
What I’ve observed
The organisations that I worked with have some unspoken conflict between two very different tribes: on one side, people that want to move fast, test new products or services and abandon what doesn’t work. On the other side, people must maintain the different assets that underpin the company’s operations. Using the accounting jargon: a group of people that manage OPEX and a separate group that manages CAPEX. It might not be a problem since companies had operating like that for decades. Or is it?

Let’s use an example…
Let me use an example that you might recognise. Imagine an organisation in the logistics domain. They own warehouses and a fleet of trucks. The business proposition is focused on small businesses, who can act as end-to-end logistic partners, helping the small businesses to have a more significant geographic footprint. They have been operating since the 1980s when business transactions were done via salespeople (in-person), phone or fax. Back then, the company set up an IT department to manage the technical assets, such as phones and faxes. As the company evolved and software became the norm, the IT department now manages physical assets such as the data centre, phones and laptops and digital assets such as software and software licenses. The IT department mainly manages CAPEX, given that most assets are physical. They also have a sales and marketing department, where they transitioned from in-person sales to digital sales. They target the same small businesses, but these small businesses are leveraging the internet to sell their goods. This department manages OPEX since they spend the budget on marketing campaigns, such as social media ads.
So what?
So what?, can be the question in your head. Well, I didn’t transcribe CAPEX in the blog post. One attractive property of CAPEX is that the cost cannot be deducted in the year it is paid. It is capitalised across the lifecycle of the asset. This means that organisations maximise the use of assets under CAPEX, and people directly responsible for managing such assets must understand their lifecycle (which can vary from a couple of years to decades). On the other hand, OPEX can be offset in the same year (taxes like VAT).
It provides an interesting challenge: OPEX and CAPEX have different time horizons, and people will have different behaviours when applied to assets (such as a data centre or a marketing campaign). It can affect decision-making, risk-taking, innovation, and overall organisational culture.
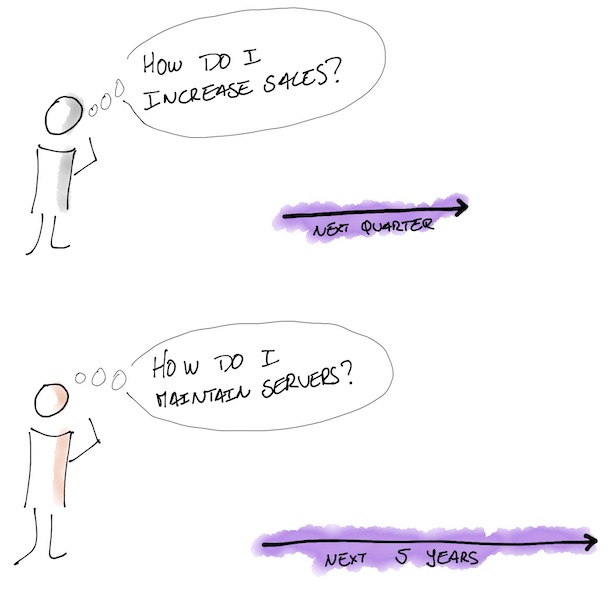
At an organisational level, it poses a tall challenge: as time passes, the group that manages OPEX wants to move faster, and the group that manages CAPEX needs to maintain assets with a long lifecycle. In other words, organisations (as described in the example above) have IT to manage CAPEX, and sales type of groups manage OPEX. Of course, it is a simplified view, but it should give you an idea.
When an organisation undergoes a digital transformation, this tension becomes apparent. Because people manage assets using methods that suit the finance and accounting constraints, their behaviour and mental models fit those methods. For example, if an IT department evolves as in the previous example, it will likely apply waterfall methods to software development, producing long lead times. But hey, if those are the methods people know, how can they do it differently? Of course, each organisation is different, and the behaviour that I described is more latent in organisations that are not digital native.
The organisations that are winning in the digital space have short feedback cycles. By having short feedback cycles, they can learn quickly from the people using their services and/or products, having the opportunity to correct course (if they miss the mark) or even create new value propositions. By opposition, if you have long feedback cycles, you are playing catch-22, and competition (is likely) to outpace you. And I realised that companies with long feedback cycles trying to transition to a digital model but have yet to succeed in it have a clear split between groups managing CAPEX and OPEX.
Focus on the environment, not on people
Kurt Lewin wrote in 1936 the following equation:
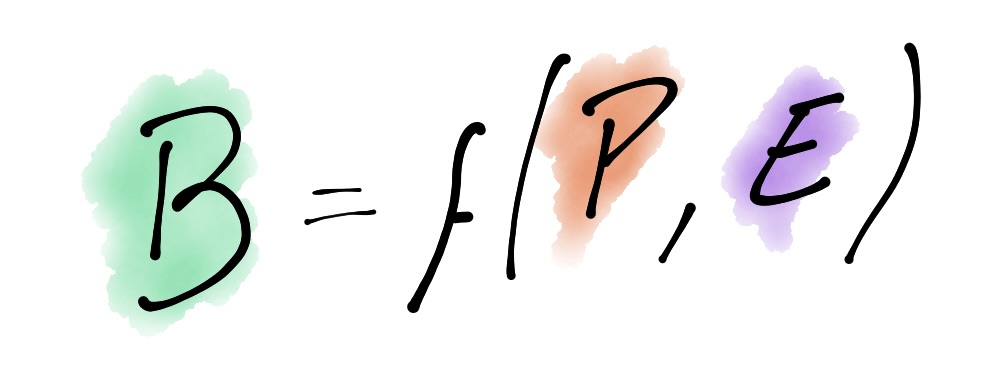
It means that behaviour is a function of a person in their environment. Let that sink in for a moment.
Unfortunately, it is common in digital transformation to tell people how they should behave rather than actually change the environment where people conduct their work. And it is one of the strong reasons why those digital transformations fail. Without the proper incentives in the organisation, the behaviour will remain the same.
If you want a digital organisation, you must revisit your finance and accounting model. Those models reinforce behaviours that are different from a truly digital organisation. In the organisations I work with, it is a topic I put early on the table. Without adequate financial constraints, digital transformation is at odds.
Some use cases to foster the environment
Let me describe some use cases. I’m telling some of my experiences, where the goal was to increase the cooperation of different groups. As humans, we relate to examples. But be aware: it is not an exhaustive list of solutions, and I’m looking for feedback. What can other use cases help foster the environment?
Move your IT real estate to an OPEX model
Moving your IT real estate to an OPEX model is the obvious use case. In the example of the logistics company, by moving their workloads from the data centre to the cloud, the group managing the data centre will stop managing CAPEX (or a big chunk of CAPEX). They will be incentivised to think in smaller timelines since they don’t have assets to depreciate.
Platform as a product
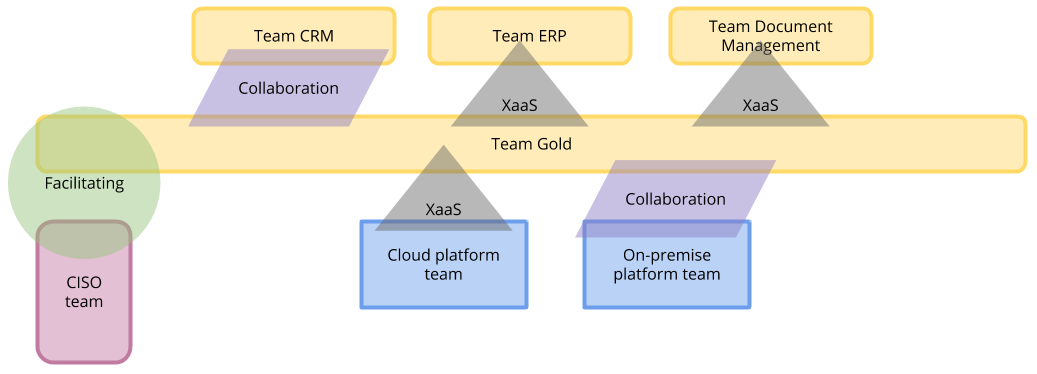
Platform as a product is gaining relevance in the IT world. In terms of CAPEX and OPEX, the platform can have assets that are managed via CAPEX but offer services that are OPEX based. It requires financial and accounting experts in the platform to have the proper mechanisms in place. And this model is not new: the cloud providers use it. The platform as a product has been gaining popularity in recent years. The IT industry realises that everything needs proper product management to be successful (I’m referring to product folks that scan the problem space to find opportunities, not people with a “product” role where their job is to be gatekeepers for software teams). Team Topologies have extensive material on this topic.
Focus on the capability, not on the type of role
Given the organisation has the ambition of being digital, there is an opportunity to have an organisational model where people from different roles (marketing, sales and IT) are together to form one capability. The capability has an outside-in view, starting with the user needs (external and internal) and what needs to be done to deliver. It is disruptive since most organisations have a cut between business and IT. This use case assumes that organisations are committed to being the best in their field and are willing to let go of the false dichotomy between business and IT. In this way, the CAPEX and OPEX blend over the different capabilities, and the people are incentivised to nurture organisational capabilities rather than manage assets.
All of the above use cases have profound implications for the sociotechnical system of the organisation. The architecture of the software needs to change to match the new boundaries, the software engineering practices need to evolve to provide fast feedback, and the structure and composition of the teams will evolve to enable a fast flow of change. And the financial and accounting processes need to be redesigned from the ground up to support it (it is the subject of the blog post, but hey, let me be explicit). It is a tall order to evolve an organisation, but with the right incentives in the environment (your organisation), the behaviour will start to change over time.
In conclusion
Any organisation is a complex system. And our industry tends to focus on the people rather than the interactions between people, technical procedures, policies and processes. However, there are better approaches than that. From complexity science, we know that interactions in a complex system are vital. Kurt Lewin was one of the modern pioneers of social, organisational, and applied psychology.
In any sociotechnical system, it is essential to understand how people are constrained and motivated to do their jobs. Changing the constraints and policies at the financial and accounting level allows people to think in different ways to deliver value, increasing the feedback cycles. An organisation can maximise its digital capabilities if they have shorter feedback cycles.
I would love to hear from you. What are the other constraints that you see at play? What are the success and horror stories that you experienced? You can leave a comment or contact me directly.
]]>




{kind=link}