NDepend, first impressions on a static code analyser
01 October 2017
During my career, I learned on the hardest way how a poor codebase can be harmful to the business. I witness behaviours in teams such as:
- Missing code reviews. How can we be a team, if we do not communicate?
- No coding standards. At least settle the capitalisation style?
- Testing. Wait, spending time writing tests?
Luckily, I also worked as part of great teams, whereby everyone was committed to the code quality, continuous learning and discussing in how we can improve it, moving us faster.

Technical debt for dummies. Source: https://twitter.com/carnage4life
Recently, I started investing some time understanding in how we can leverage the available tools in our technological space to enhance our codebase and at the same time reducing the time spent on some tasks, such as code reviews. I firmly believe that a (manual) code review should be focused on architectural principles (how the code fits in the grand scheme of our applications landscape), and less on topics as naming conventions or test coverage. The latter can be done by static code analysers, freeing up the time of the reviewers for the former.
NDepend, how can it help?
A good codebase not only is readable and maintainable but is it also performant. Sometimes we introduce potential bottlenecks in some forms or shapes, such as the usage of a class instead of a structure, or leaking the scope of a variable. The next developer responsible for extending or using the code will not know the initial intention (it only lives in our head), but she/he only knows the intention of our code. If a variable has a bigger scope that it should, someone will “leverage” it in the next feature iteration, introducing unintended behaviour or even bugs. The previous scenario is an example of technical debt (introduced by Ward Cunningham in 1992, with a more verbose explanation by Martin Fowler).
NDepend translates the technical debt and code smells to useful dashboards, using static code analysis technics. Let’s give it a spin.
Apply it to a project
After install and configure NDepend, I decide to use it on a pet project. The pet project is relatively small, with a fair number of unit and acceptance tests. Running NDepend with the default settings I got:
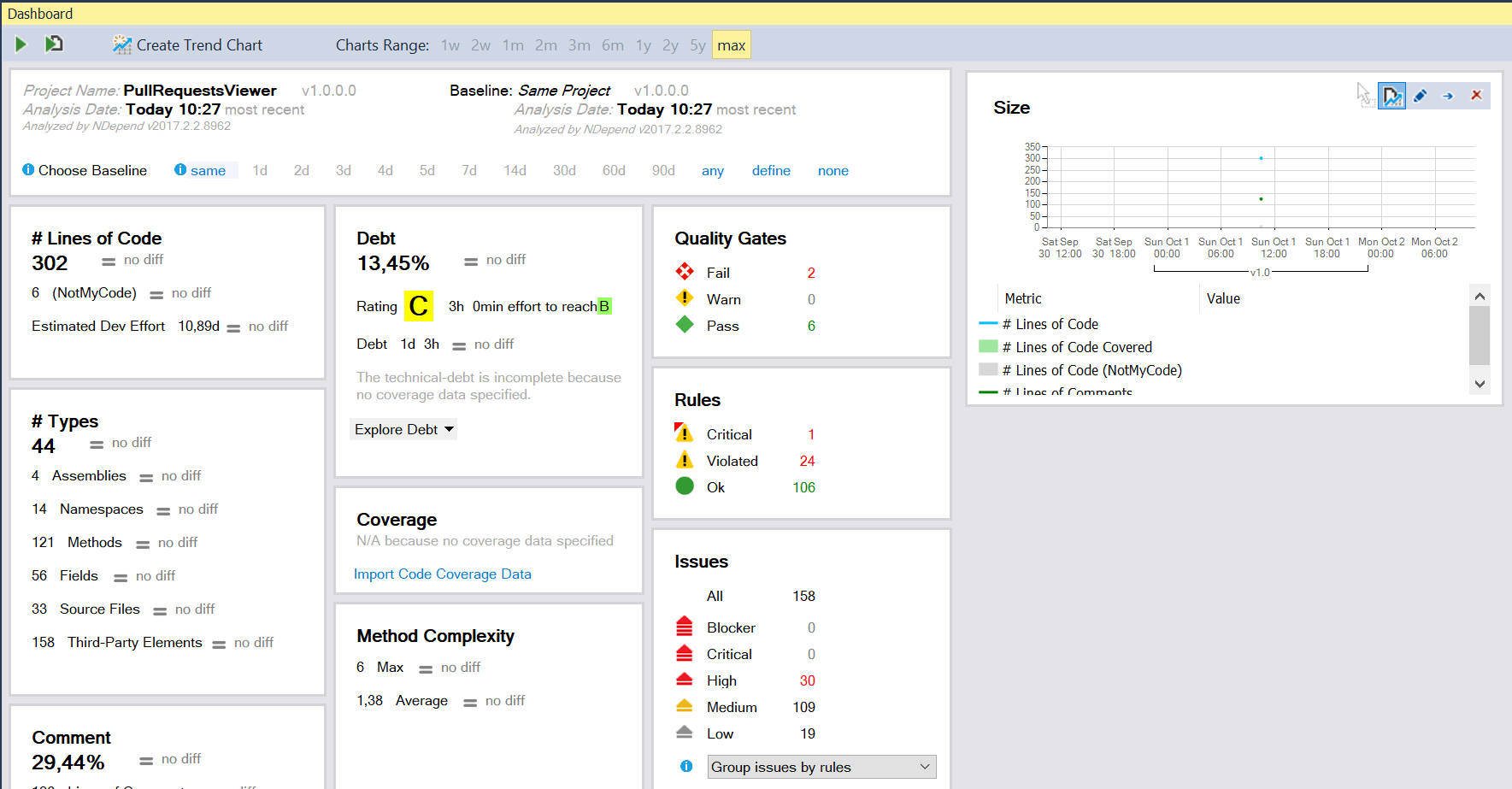
NDepend result on Pull Requests Viewer project
I was surprised with the results since it failed some Quality Gates and violated some Rules. Doing further digging, I found the “bad boy”, who violate one of the quality gates:
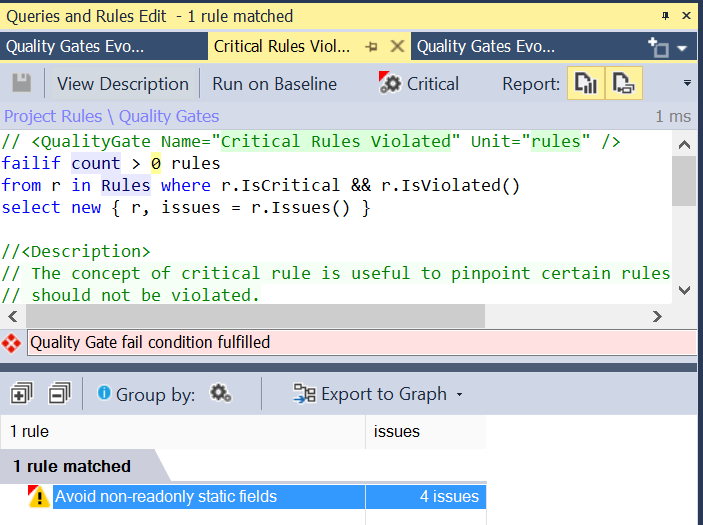
Violated rule for the quality gate
If we expand the rule it pinpoints to the code line where the rule is violated, and at the same time provides the explanation of the rule, thus all the details behind the rationale of the rule, and how it impacts the current solution. No matter how careful we are with our codebase, sometimes some oversight happens, and it will pop up in the future. In the end, we are humans, and we have machines capable of run all these rules.
NDepend provides a wide range of pre-defined rules, but it also allows the user to tweak and tune them, or even create new rules based on the project/company standards. It implements a LINQ-based query language (CQLinq), the syntax is intuitive and user-friendly (for developers with C# background).
Where it can shine
Although we all envision a greenfield project, in reality, most of the time, we work with legacy codebases. Don’t get me wrong, legacy code bases pay our salaries (borrow from Eric Evans through Mathias Verraes):
“Legacy systems make money. You should hope that one day your system becomes a legacy system.” @ericevans0 at @ExploreDDD
Mathias Verraes (@mathiasverraes) 21st September 2017
I did a fair bit of code refactors on legacy code bases, morphing the state to a maintainable structure. Although I discover some useful techniques like the Mikado Method, a tool like NDepend would be helpful on the discovery of code/architecture smells, speeding up the refactoring work. Along with it, NDepend tracks the code base metrics across time, providing useful insights over the work done.
Continuous Integration and NDepend
The integration with some of the major CI technologies is a plus for this tool. The capability of generating reports on each commit/merge empowers the teams with the right metrics at the right team, helping them to tackle the problems sooner rather than later, avoiding the technical debt bogeyman.
The documentation is extensive and detailed, most of the times providing images with feature examples over OSS code bases (here it can be found the report of the popular NodaTime package).
Final thoughts
Although this was my first impression of the tool, and I used it for a couple of hours during the weekend, it proved to be a powerful tool to be added to my toolbox. It unveils some underline issues with a small project as the Pull Requests Viewer, helping me to clean the codebase and think of better solutions to the reported issues.